
本文来自微信公众号:数字生命卡兹克,作者:数字生命卡兹克,原文标题:《看到现在的毕业生被AIGC查重折磨,我有话想说。》,题图来自:AI生成
高校引入AIGC检测工具判定论文AI生成比例,导致部分学生因检测结果无法毕业。文章指出检测技术存在原理缺陷(如困惑度分析、黑箱分类器),误判逻辑荒谬,将流畅文本视为AI生成,忽略学生真实写作过程,同时质疑检测工具商业化收费不合理,呼吁避免以技术指标取代人文教育价值。
• 🤖技术原理缺陷:AIGC检测依赖困惑度、分类器与风格建模,误判逻辑自相矛盾。
• 📉误判案例讽刺:王勃《滕王阁序》若用AI检测工具分析,可能被判定为AI生成。
• 😤荒谬检测逻辑:文本越流畅越像AI,语法错误反而成“人类写作特征”。
• 💰商业化利益驱动:检测服务收费高昂,成本与定价严重不匹配。
• 🔍信任危机本质:用AI检测结果替代人性判断,演变为技术对人格的否定。
• 📜未来隐忧警示:若过度依赖AI检测,人类可能因恐惧误判而丧失创作自由。
我其实一直都很赞成AI的快速发展,很少会看到,让我眉头一皱的AI应用场景。
甚至会有点出离了愤怒。
因为可能本心是好的,但是这个方法,却把好心,变成了一个让我非常痛心却又觉得无奈的事件。
这个事情就是,马上毕业季了,很多的学校,为了整治学术不端行为,所以对学生们的论文,除了原来的查重检测之外,引入了AIGC检测。
大概就是用一些所谓的AI检测工具,来检测你的论文里,AI生成的含量有多少。
如果你的AIGC检测比例,如果高于一定的指标,就会无法毕业。
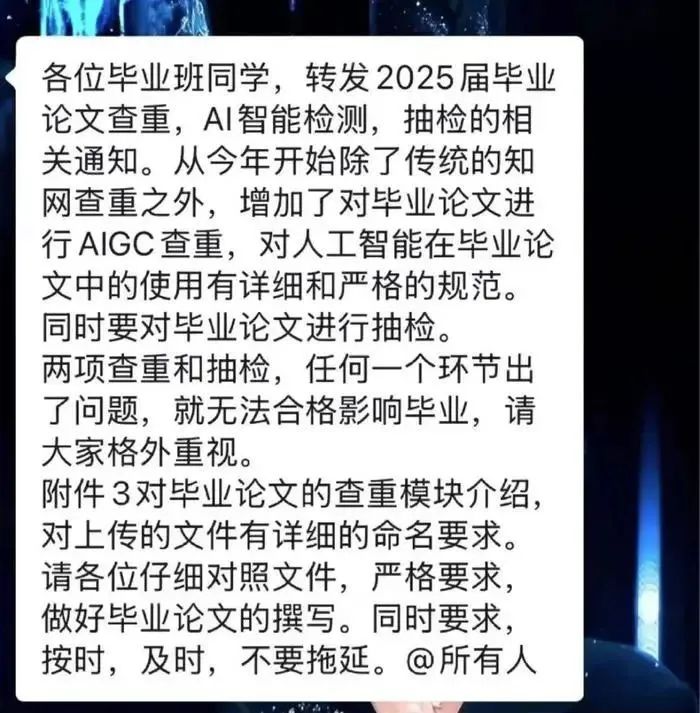
起初我以为这种只是一些造谣的图,在我实际查证之后,我发现,是真的。
已经有多所大学,启动了AIGC检测,并且有明确的指标。
比如4月9日,四川大学教务处发布的《关于开展2025届本科毕业论文(设计)学术不端行为检测工作的通知》中,就明确提到了,20%和15%这两个比例。
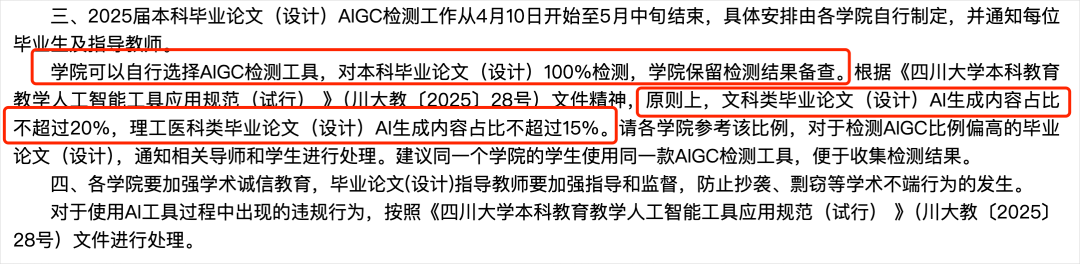
不止一个,还有很多。
如果你去Google上搜一个关键句:关于2025届本科毕业论文(设计)试行AIGC检测的通知。
你就能看到,大概有哪些学校,在开始实行AIGC检测了。
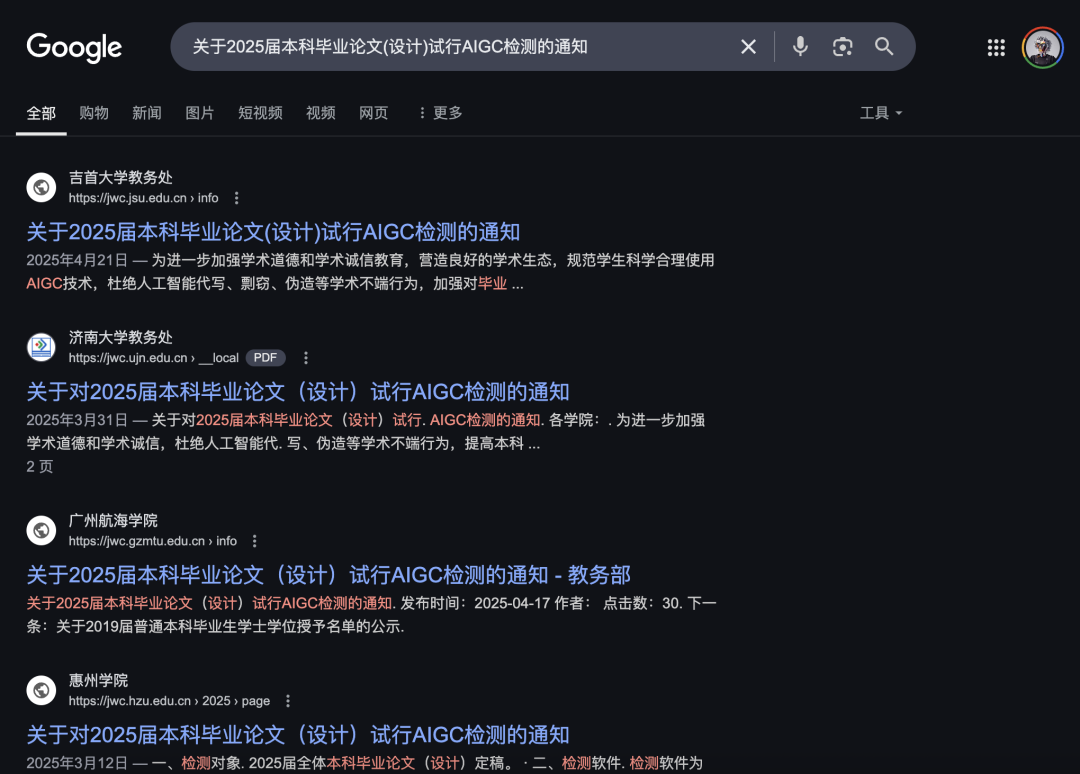
你如果去小红书在看看,搜索关键词:AIGC论文。
能搜到一大堆的吐槽贴,还有掺杂在里面想捞一笔的所谓几款降重的广告。
我不知道你们看完这些学生们的吐槽以后是什么感觉。
我能感受到的,只有愤怒、痛心、还有无奈。
说实话,我一直是AI坚定的支持者。
我写AI、研究AI,见证AI从最开始笨拙到如今绝大多数人无法看到上限的全过程,我比99.99%的人,都更相信它的未来。
但我从没想过,它会以这样一种粗暴、冷漠、失控的方式,误伤那些本该最被保护的人。
因为知道AIGC检测原理的人,就会知道,这玩意,在论文场景上,根本不靠谱。
它的最底层原理其实很简单,说白了就一句话:“用另一个AI,去判断这是不是AI写的。”
也就是说,我们现在在干一件极其荒谬的事情。
“让AI审判AI,最后把结果扣在人类头上。”
这事实在太特么蠢了。
它不懂你是什么背景,不知道你是不是通宵写的,不知道你有没有复查文献、推敲措辞、修改逻辑,它只看语料、风格、用词概率。
只要你写得太流畅、太规范、太有逻辑,不好意思,可能就会被判成AI写的。
它不管你是不是人肉手写,只要你像是模型生成,它就把你打成AI。
那我想稳稳,什么才不是AI呢?那到底什么才是“人”写的呢?
是我这种上不了啥台面的,错字连篇的公众号文章吗?是跟我一样的人类撰写声明吗?是只有打错字、病句频出、思路跳脱才算一个人吗?
我真的很想问一句:这最后要的,到底是人类的思维,还是AI的漏洞?
这不是一个简单的误判。
这使我觉得,很多学校的教育系统、技术系统、管理系统,对AI认知的深度误解与草率滥用。
我没有那么懂技术,但是根据我自己过去的知识和有限的了解,现在主流的AIGC检测工具,依赖的核心算法,我大概会归为3类,这3类,在检测文本是不是AI生成的上,各有各的问题。
第一类,叫困惑度与熵值分析。
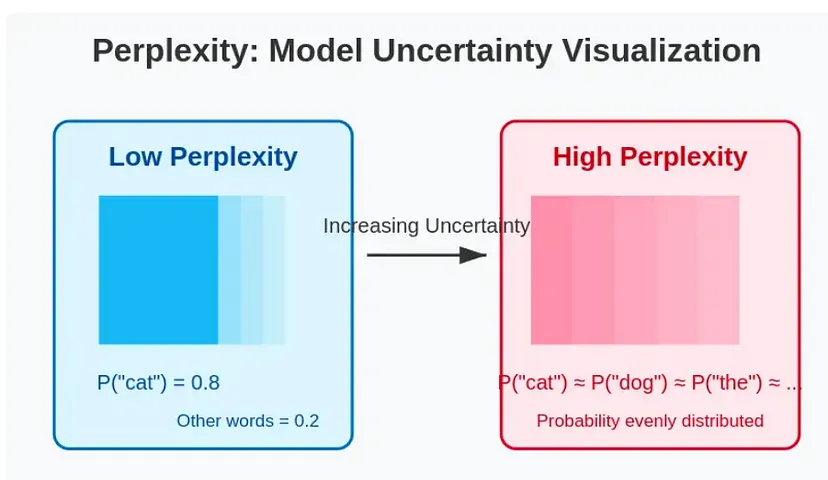
这套逻辑其实特别搞笑。
它的底层逻辑是这样的:AI模型生成文字,通常很顺,因为它是从一堆可能性中挑概率最高的词来生成。
在专业术语上,跟困惑度相关的叫文本熵值,就是基于信息论的随机度量。
一个文本的熵可以通过字词分布来计算。所以,AI生成的文本可能在某些统计特征上熵较低,过于均匀或模式化,而人类文本熵值更高或者分布不同。
所以,如果你写得也很顺,语言平滑、逻辑清晰、用词自然,这个系统就觉得你“哦,这过于不让人困惑”了,那没跑了,你一定是AI。
相反,如果你写得磕磕绊绊、断断续续,错别字连篇、语法错误频发,让人满脑子困惑,卧槽,那这才像人啊!
这就好比你去应聘一个岗位,答得太好被质疑背稿了,答得磕巴反而觉得你有灵魂。
这检测逻辑,离谱得很离谱。
第二种,是我觉得最能无语的,机器学习分类器。
他们会喂给AI一个大数据集,里面有人写的和AI写的例子,然后训练它去分辨你是哪边。
说实话,这方法在理论上没问题,但实际用起来,实在是过于操蛋了。
你写得像训练集里的AI,它就觉得你是AI。
而且你别指望它告诉你为啥判你是AI,它不会说,“因为你这句话太GPT了”,它只会说:“我感觉你好像有内味。”
一个黑箱模型对你的整篇论文说:“你让我感到很GPT。”
你告诉我,这是什么判决依据?是超能力吗?那我说我感觉你像有十个私生子的人,你就有十个私生子吗?这不搞笑吗。
最后一种,叫句法和风格特征建模。
除了统计层面的困惑度,还可以从句法结构和写作风格入手建模人类与AI的区别。
人写文章嘛,有时候写死鼻子老长的长难句,有时候短句。
灵感上来了写得鸡飞狗跳文风跟妖孽一样,没灵感时写得跟新闻稿一样。
所以人类写作的风格是突突突、停,波动大的。
AI呢?它喜欢平稳输出,平平滑滑没啥高低起伏。
于是,之前GPTZero引入了一个指标,叫突发度(Burstiness),用来衡量整篇文章中句子之间困惑度的变化程度。
除了突发度之外,还可以提取更多句法和文体特征,比如平均句长、从句使用频率、常见连接词的密度、主动被动语态比例、学术词汇占比等等。
但是,那我想问了,你见过几个熬夜赶毕业论文的人,是一边写一边保持文学高潮的吗?
从头到尾都是神之一手、李白附体,全篇都是《滕王阁序》那种文笔?从古至今有几个那种神仙啊?
但是等等,关键那AIGC检测,说《滕王阁序》的AI生成度疑似74%啊。

甚至能不止74%,还能给你拉满。
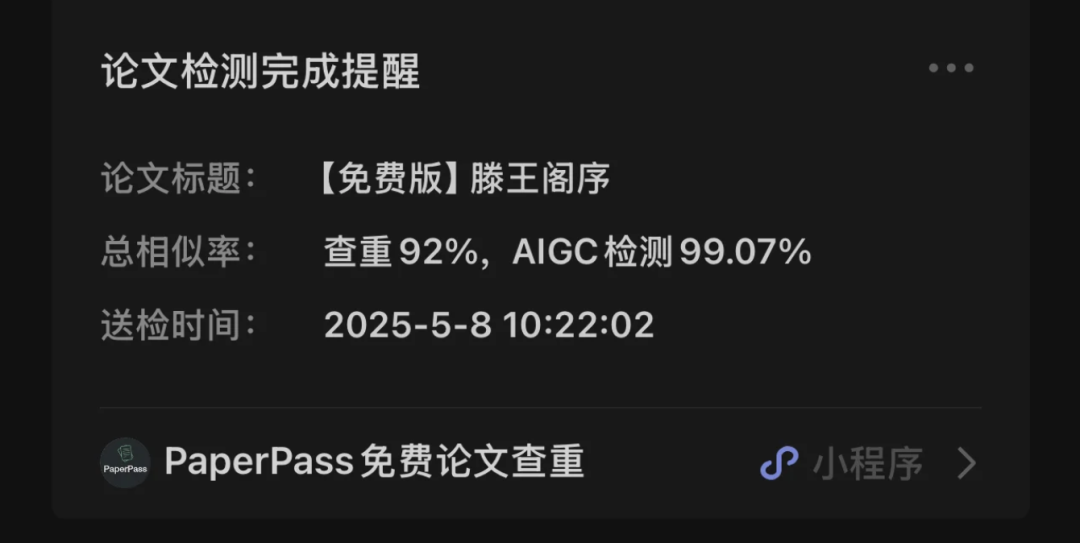
咋地,王勃穿越者实捶呗?在2025年用DeepSeek生成了一篇《滕王阁序》,吃着火锅唱着歌带回了公元675年了呗?
所以,除了无语,还是无语。
方法就是这些方法,推理成本就现在这样,大家也都有个数。
你就按DeepSeek R1参考,百万Token,也就是大概75万字,8块钱人民币。
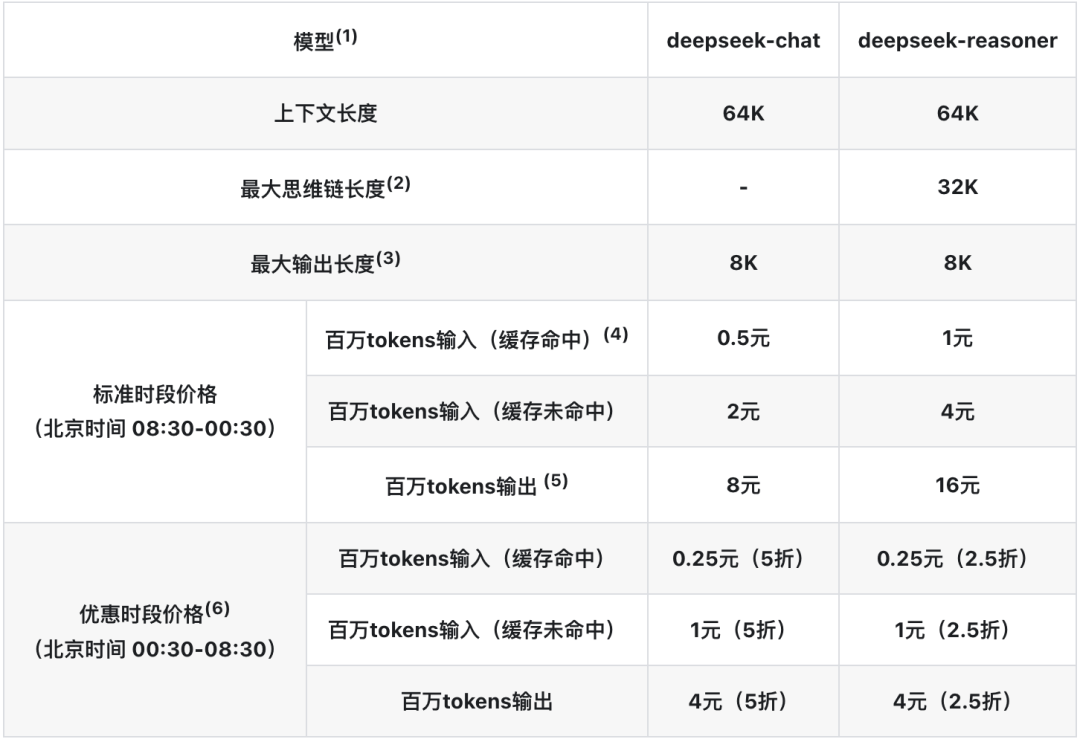
你再看看知网的AIGC检测服务。
1千字2块钱。
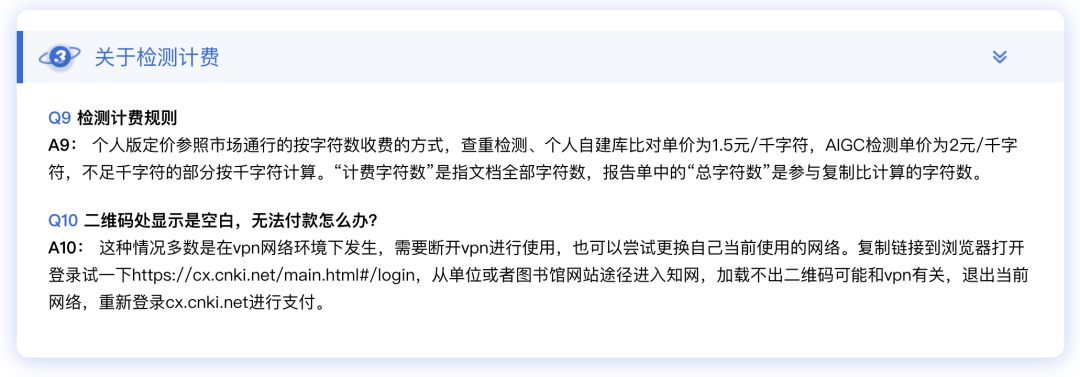
我想问问,这是在拿24K纯钛合金的英伟达H888在推理吗?钱到底进了谁的口袋呢?
荒谬,至极。
而我最痛心的是,大部分使用这些检测工具的学校、导师、管理者,他们可能根本不知道这些事情。
他们只看到“AI率:74%”,就当成铁证。一句话,把一个学生的努力打成零分。
一个通宵写稿的晚上,一个用Word改了几十次的版本,一个在图书馆趴在桌子上睡着的凌晨。
不是AI,是人。
是人。
但你没看人,只看了分数。
而且,这种“AI率=AI写的”的推理,本身就站不住脚。
我们要清楚一点:
生成模型永远领先检测模型一代。
就像病毒传播,永远快于疫苗研究。它只能大概给出像不像,永远给不出是不是。
但现在,很多人竟然把这个像不像的结果,变成了你有没有作弊的判据。
这不是技术问题。
这是我们的信任危机。
我写AI,是因为我希望AI让我们更自由,不是希望AI让人更恐惧;
我用AI,是因为我希望它成为表达的延伸,不是希望它成为拘束的锁链。
而这场所谓的AIGC查重,本质上是:
人类用AI造了一个火,然后害怕它,最后用另一个AI,去逼普通人承认他们也起火了。
如果你非要说,问我对这个现象怎么看?
我只能说一句:
这不是AI的错,这是人类使用AI的方式,错得离谱。
用概率,盖过人格。
用模型,替代人性。
如果有一天,一个学生的泪水、他的痛苦、他的努力,敌不过一个模型的“百分之七十四的判断率”。
如果有一天,一个人要靠录像监控自己来证明是自己写的不是AI写的。
那我们这代人,也许真的,活成了AI眼中的幻觉。
因为如果再这么下去,你我终将活在一个更残忍的版本里。
不是我们被AI误伤,而是:
我们,不再敢写字了。
本文来自微信公众号:数字生命卡兹克,作者:数字生命卡兹克